Christopher Lucas addresses long-standing questions in political science using new computational methods and previously untapped datasets – including the sound of political speech.

“It’s not an exaggeration to say there’s been a revolution in the study of political science in the last two decades,” said Christopher Lucas, assistant professor of political science. In earlier eras, quantitative political scientists like Lucas were generally limited to data from sources like surveys and election outcomes. Now, he explains, “much of political life is documented on computers through social media, online news, and mobile data.” Alongside rapid advances in statistical methods, this explosion in data has dramatically changed what social scientists can study quantitatively.
In the newly digitized political landscape, Lucas situates his research at the forefront of big data and political science. One of his recent publications, “A dynamic model of speech for the social sciences” from the journal American Political Science Review, presented techniques he and longtime collaborator Dean Knox developed to analyze the sound of speech. By applying their method to oral arguments in the Supreme Court, Lucas and Knox demonstrated how vocal tone encodes crucial information that is not captured by text alone. The work typifies Lucas’ longstanding approach to complex problems in political science.
Back in graduate school, Lucas worked on a project that adapted widely used methods from computer science, originally designed to descriptively summarize large quantities of text, to better suit applications in the social sciences. Through that experience, he realized the value of interdisciplinary research that adapts methods from other fields to new questions.
“It’s not an exaggeration to say there’s been a revolution in the study of political science in the last two decades.”
“In social science, we are fundamentally interested in causal explanations,” Lucas said. “Researchers want to go a step beyond quantitative description, to an explanation of why we observe descriptive variation in the data. Off-the-shelf approaches from computer science and related fields rarely target these causal quantities directly. In the context of text data, we want to not only summarize, for example, the topics covered by the news media, but also the causal effects of that news coverage on other important behaviors, like election turnout and public opinion.”
This realization spurred Lucas’ interest in new sources of data, like political text or the sound of political speech, and his research turned toward the development of statistical methods that directly targeted substantively interesting quantities in previously ignored data sources. Combining his expertise in computational methods with a fortuitous interest in music and playing guitar, Lucas found himself asking what we might be missing in lingering, unexamined, and often-ignored sources, simply because good models for studying this complex and messy data didn’t yet exist.
Sound, including human speech, was a clear candidate for Lucas’ attention. Quantitative scholars have largely ignored audio data, arguably because methods for working with it have remained difficult relative to those available for other kinds of data, like text. Until now. Lucas developed the model of audio and speech structure (MASS), a tool that extends approaches in statistics and computer science to analyze the speech and dialogue at the heart of political communication.
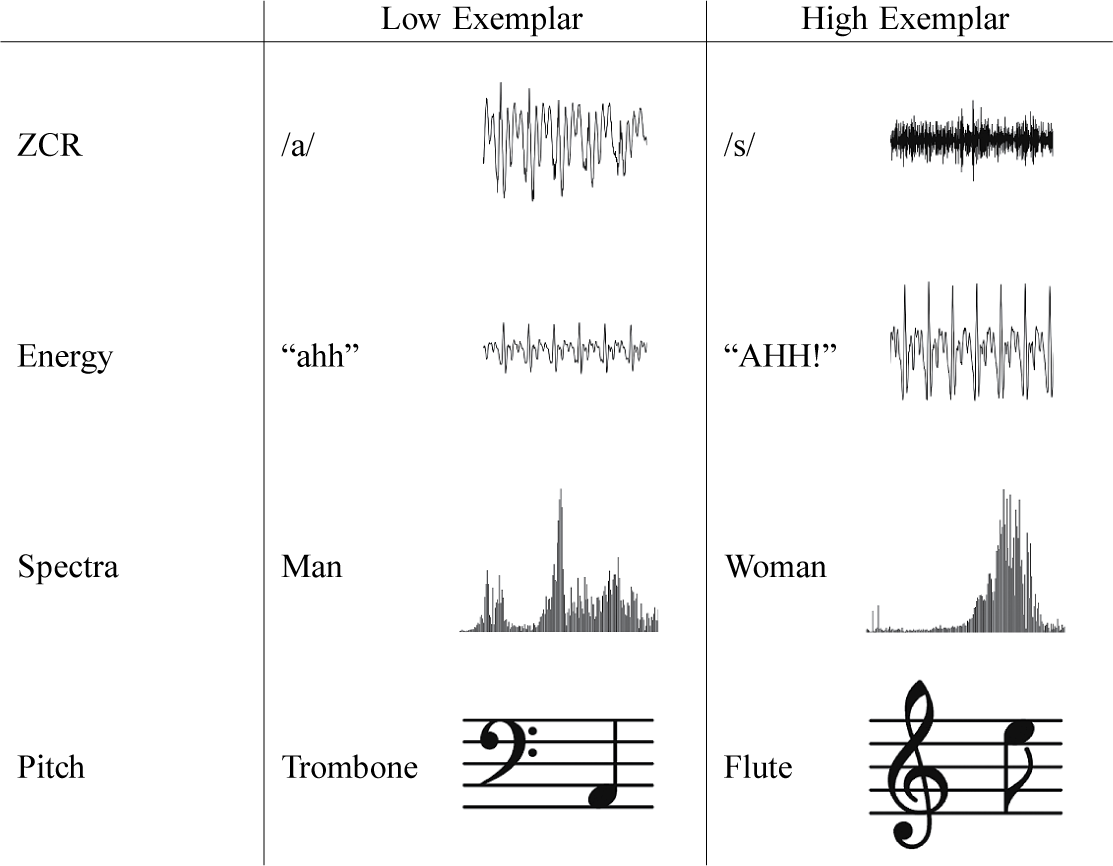
“The discarded audio channel contains information of enormous value to social scientists,” Lucas and Knox wrote in their paper. “By modeling the tone it conveys, MASS not only opens the door to new research questions but can also shed new light on existing puzzles.”
The results speak for themselves. Lucas’ paper analyzing Supreme Court speech with MASS reported that his audio-based measurements significantly outperformed earlier text-based work on predicting judicial behavior based on a justice’s expression of skepticism during oral arguments. In fact, the audio-based analysis was three times better than earlier text-based ones, a remarkable result.
Building upon this success, Lucas recently won a grant from the National Science Foundation to continue his work in computational methods for speech analysis. He will be exploring new applications for his speech analysis model, collecting new data to apply the model to different contexts, and extending the statistical power of the model, enabling researchers to do more with less data. In some ways, he approaches the work with a playful interest in tinkering with current methods.
“It’s like if you got a brand-new telescope for your birthday, the first thing you would do is point it up to the sky and see what cool stuff you could see,” Lucas said. “Then, after you see some stuff, you eventually find limits in what you can see, so you go back and work on the telescope, improving your tools so you can see more.”
“The most important thing for me has been thinking about how we can study new data in a principled way that generates valid insight into questions that have been puzzling us for a long time, while also enabling new questions.”
Lucas also has forthcoming research that continues his fruitful interplay between applications and methods. One such project examines the dynamics of conversation between people, with an added component studying the effect of speech on listeners not involved in the conversation. This work has clear applications to political debate and voting behavior, as does Lucas’ upcoming work on image and video data, including controversial and increasingly sophisticated deepfakes. Visual data is another notoriously large and complicated dataset that political scientists have been interested in since at least as early as the 1960 Kennedy/Nixon debates, but have so far been unable to tap in a robust and principled way.
“This isn’t a temporary phenomenon,” Lucas observed. “We’re not near the point of data availability leveling off, so there’s a lot of appreciation in the field that having the tools and knowledge to study it in a way that produces correct answers is incredibly important.” According to Lucas, some of the most pressing challenges are practical – universities often don’t have sufficient computing infrastructure or support for computational social sciences, where datasets like Lucas’ may range in the hundreds of terabytes.
Luckily, WashU’s political science department is very strong in political methodology, with an intentional focus on computation and support for this work at all levels, including from Chancellor Andrew Martin, who is a Fellow of the Society for Political Methodology. The ongoing Digital Transformation Initiative in Arts & Sciences also aims to bring even more expertise and resources to data science efforts in coming years.
When it comes to analyzing big, unstructured datasets, Lucas advises, don’t be deterred by messiness. “We often ignore potentially rich sources of data, not because we think they don’t matter, but because analysis is complicated and messy,” Lucas said. “The most important thing for me has been thinking about how we can study that data in a principled way that generates valid insight into questions that have been puzzling us for a long time, while also enabling new questions. It’s really exciting to expand the scope of what we can do as a field.”